

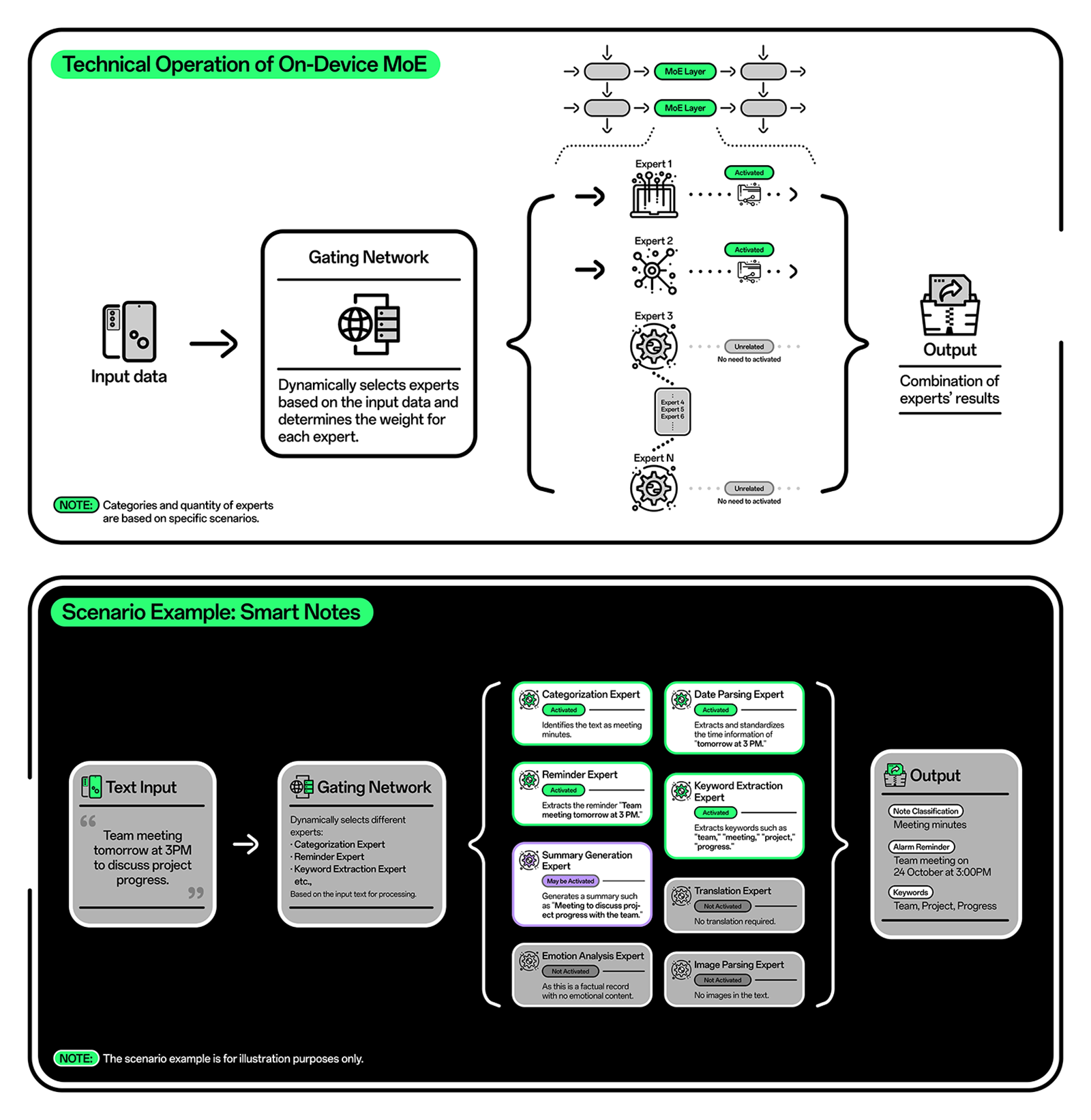
OPPO has achieved a major breakthrough by becoming the first company to implement the Mixture of Experts (MoE) architecture on-device. This advancement in AI processing efficiency opens new possibilities for more advanced and flexible AI integration on mobile hardware, setting the stage for future innovations.
As AI technology progresses, more tasks are performed directly on devices. However, larger AI models demand substantial computational power, potentially affecting device performance. In response, OPPO has collaborated with leading chipset providers to implement MoE architecture on-device, addressing these challenges.
The MoE architecture improves efficiency by dynamically activating specialized sub-models, or “experts,” to handle specific tasks. Lab tests show that this architecture accelerates AI task speeds by approximately 40%, reducing resource demands, optimizing energy consumption, and ensuring faster AI responses. This also results in longer battery life and enhanced privacy, as more tasks are processed locally on the device without requiring data transfers to external servers.
OPPO’s milestone in bringing MoE on-device is a significant leap forward, lowering computational costs and making it possible for a wider range of devices, from flagship to affordable models, to perform complex AI tasks. This advancement will drive broader AI adoption across the industry, making cutting-edge AI capabilities accessible to more users.
OPPO remains dedicated to advancing AI technology, with over 5,860 patent applications in the AI field and the establishment of an AI Center in 2024. This center consolidates OPPO’s AI research efforts, aligning with the company’s mission to provide high-quality AI experiences to users worldwide. By continuing to innovate, OPPO is extending the reach of advanced AI-powered features across its devices, ensuring that AI becomes more accessible to users across all product categories.